
รู้จัก LLMs’ Explainability การเข้าใจกลไกสมอง AI หนึ่งใน Tech Trends 2025 ที่จะมาเปลี่ยนโลกเอไอ
เคยสงสัยกันไหมว่าเวลาเราใช้งาน AI คำตอบที่มันยิงมาให้เรานั้น จริงๆ แล้วมาจากไหน? มันคิดยังไง วิเคราะห์แบบไหน ถึงได้คำตอบเหล่านั้นออกมา ในโลกตอนนี้ AI มีความสามารถมากมาย แต่สิ่งที่ยังเป็นปริศนาใหญ่คือ “มันทำแบบนั้นได้ยังไงกันแน่?”
โดยเฉพาะกับโมเดลโครงข่ายประสาทเทียมขนาดใหญ่หรือที่เรียกว่า Large Language Models (LLMs) ที่ซับซ้อนจนเราแทบมองไม่เห็นกระบวนการคิดภายใน พวกมันเหมือนกับกล่องดำลึกลับที่สร้างผลลัพธ์สุดล้ำออกมา แต่ไม่มีใครบอกได้ชัดๆ ว่าข้างในเกิดอะไรขึ้นบ้าง นี่แหละคือที่มาของคำว่า “ปัญหากล่องดำ”

ปัญหานี้ได้กลายเป็นจุดเริ่มต้นของความพยายามในการพัฒนาเทคโนโลยีที่เรียกว่า LLMs’ Explainability หรือการอธิบายความสามารถของ AI เพื่อให้เราเข้าใจและตรวจสอบการทำงานภายในของโมเดลได้ชัดเจนยิ่งขึ้น ทาง CB Insights ซึ่งเป็นบริษัทวิจัยด้านการลงทุนที่รวบรวมข้อมูลสตาร์ทอัพทั่วโลก ได้ชี้ให้เห็นว่าเทคโนโลยีนี้มีแนวโน้มจะกลายเป็นนวัตกรรมสำคัญที่เริ่มเป็นที่พูดถึงมากขึ้นในปี 2025
ความพยายามในการไขปริศนากล่องดำ AI
จากรายงานของ CB Insights เผยว่านักวิจัยจึงกำลังมุ่งมั่นศึกษาเทคนิคต่างๆ เพื่อทำความเข้าใจและควบคุมการทำงานของ LLMs ให้ดียิ่งขึ้น โดยการศึกษาการอธิบาย LLMs แบ่งออกเป็นสองแนวทางหลัก คือ Local Analysis และ Global Analysis

- Local Analysis: มุ่งเน้นไปที่การอธิบายผลลัพธ์เฉพาะเจาะจง โดยพยายามตอบคำถามว่าทำไม LLM ถึงให้คำตอบนั้นๆ เทคนิคที่ใช้ เช่น Feature Attribution Analysis ซึ่งวิเคราะห์ว่าปัจจัยใดมีน้ำหนักมากที่สุดในการตัดสินใจของโมเดล และ Dissecting Transformer Blocks ซึ่งเจาะลึกการทำงานของส่วนประกอบย่อยๆ ภายในโครงสร้างของ LLM
- Global Analysis: มุ่งเน้นการทำความเข้าใจการทำงานของ LLM ในภาพรวม เทคนิคสำคัญคือ Probing-Based Methods ซึ่งใช้ชุดข้อมูลทดสอบเพื่อประเมินความรู้ความเข้าใจของโมเดลในด้านต่างๆ เช่น ไวยากรณ์ ความรู้ทั่วไป และ Mechanistic Interpretability ซึ่งเป็นแนวทางที่น่าสนใจแต่ยังอยู่ในขั้นตอนการวิจัย โดยเปรียบเสมือนการ "reverse engineer" หรือการแกะรหัส LLM เพื่อทำความเข้าใจกลไกการทำงานในระดับลึก
หากนำมาเปรียบเทียบกันง่ายๆ Global Analysis คือการศึกษาทั้งเล่มเพื่อทำความเข้าใจระบบทั้งหมด แต่ Local Analysis คือการตรวจสอบเฉพาะจุดนั่นเอง ความก้าวหน้าในการอธิบายความสามารถของ LLMs จะนำไปสู่การประยุกต์ใช้ที่หลากหลายและทรงพลังยิ่งขึ้น เช่น
- Model Editing: การแก้ไขและปรับแต่งโมเดลให้ทำงานได้แม่นยำและตรงตามความต้องการมากขึ้น
- Enhancing Model Performance: การเพิ่มประสิทธิภาพของโมเดลให้มีความแม่นยำ ลดข้อผิดพลาด และเข้าใจบริบทได้ดีขึ้น
- Controllable Generation: การควบคุมผลลัพธ์ที่ LLM สร้างขึ้น เช่น การลด Hallucinations (การที่โมเดลสร้างข้อมูลที่ไม่ถูกต้องหรือแต่งเรื่องขึ้นเอง ที่เราเรียกกันว่าอาการ AI หลอน) และการควบคุมให้โมเดลสร้างเนื้อหาที่สอดคล้องกับหลักจริยธรรม
แม้ว่างานวิจัยด้านการตีความและอธิบายความสามารถของ Large Language Models (LLMs) จะยังอยู่ในช่วงเริ่มต้น แต่ความก้าวหน้าล่าสุดได้เผยให้เห็นถึงศักยภาพในการขยายขอบเขตการตีความและทำความเข้าใจการทำงานของโมเดลเหล่านี้ โดยเฉพาะอย่างยิ่งจากงานวิจัยของสองบริษัทชั้นนำอย่าง Anthropic และ OpenAI
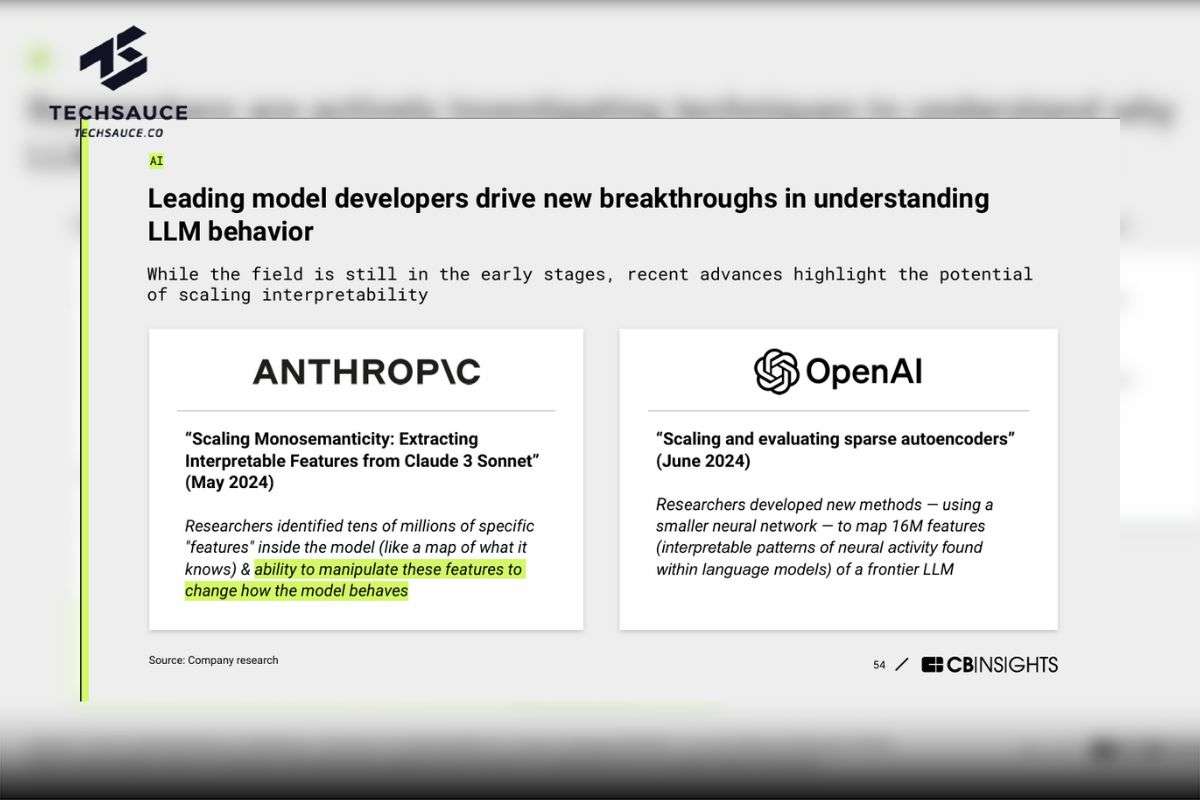
Anthropic: ในงานวิจัย "Scaling Monosemanticity: Extracting Interpretable Features from Claude 3 Sonnet" (พฤษภาคม 2024) นักวิจัยของ Anthropic ได้ค้นพบ ‘Features’ จำนวนหลายสิบล้านรายการภายในโมเดล Claude 3 คุณลักษณะเหล่านี้เปรียบเสมือนแผนที่ความรู้ของโมเดล ที่สำคัญคืองานวิจัยนี้แสดงให้เห็นถึงความสามารถในการจัดการคุณลักษณะเหล่านี้เพื่อเปลี่ยนแปลงพฤติกรรมของโมเดล ซึ่งเป็นก้าวสำคัญในการควบคุมและปรับแต่งการทำงานของ LLMs
OpenAI: ในงานวิจัย "Scaling and evaluating sparse autoencoders" (มิถุนายน 2024) นักวิจัยของ OpenAI ได้พัฒนาวิธีการใหม่ในการทำแผนที่คุณลักษณะจำนวนมากถึง 16 ล้านรายการภายใน LLMs ซึ่งช่วยให้เราเข้าใจการทำงานภายในของ LLMs ที่ซับซ้อนได้ดียิ่งขึ้น เหมือนกับการส่องกล้องเข้าไปดูว่าสมองของ AI ทำงานยังไง
การทำความเข้าใจการทำงานภายใน LLMs สำคัญอย่างไร ?
การอธิบายพฤติกรรมของโมเดลเป็นกุญแจสำคัญในการสร้างความไว้วางใจ โดยเฉพาะในอุตสาหกรรมที่มีการกำกับดูแล เช่น การแพทย์ การเงิน และยานยนต์ไร้คนขับ ความก้าวหน้าในด้านนี้จะช่วยผลักดันการนำโมเดล AI ที่ซับซ้อนมาใช้อย่างแพร่หลายมากขึ้น
นอกจากนี้ การทำเข้าใจการทำงานของ LLMs จะช่วยลดปัญหา AI หลอน (Hallucination) ที่เป็นปัญหาที่แก้ไม่รู้จบของโมเดล LLM นอกจากนี้ ยังนำไปสู่การประยุกต์ใช้กับการเทรนข้อมูล AI และการปรับปรุงประสิทธิภาพการทำงานของ AI
บริษัทสตาร์ทอัพที่มุ่งเน้นด้าน Mechanistic Interpretability กำลังพัฒนาเครื่องมือเพื่อให้ธุรกิจสามารถควบคุมและใช้งานโมเดลได้อย่างมีประสิทธิภาพ นี่ถือเป็นตลาดที่น่าจับตามองสำหรับโอกาสด้านการลงทุนและความร่วมมือ แม้ผู้พัฒนา LLM รายใหญ่จะเริ่มนำเสนอเครื่องมือเหล่านี้ด้วยในอนาคต
ตัวอย่างบริษัทในกลุ่มนี้ ได้แก่ Martian, Guide Labs, Goodfire AI, Leap Laboratories, EleutherAI และ Iluvatar ซึ่งต่างมุ่งสร้างเทคโนโลยีเพื่อเพิ่มความสามารถในการตีความและควบคุมโมเดล AI
ข้อมูลจากรายงาน CB Insights Tech Trends 2025
ลงทะเบียนเข้าสู่ระบบ เพื่ออ่านบทความฟรีไม่จำกัด
RELATED ARTICLE

คอมตัมคอมพิวติ้ง ตอนนี้ไปถึงไหนแล้ว ? สรุปความก้าวหน้าควอนตัมจากงาน NVIDIA GTC 2025
งาน NVIDIA GTC 2025 เป็นปีแรกที่มีการจัดเวทีพูดคุยเกี่ยวกับควอนตัมคอมพิวติ้งโดยเฉพาะ (Quantum Day) ซึ่ง NVIDIA ในฐานะเจ้าภาพ และผู้ขับเคลื่อนการประมวลผลแบบ Accelerated Computing จึ...
 0
0

ญี่ปุ่น ใช้ AI และเทคโนโลยีอะไร ในการรับมือแผ่นดินไหว ?
เหตุแผ่นดินไหวในเมียนมาที่ส่งผลกระทบมาถึงประเทศไทย สร้างความตระหนักถึงความเสี่ยงด้านแผ่นดินไหวที่อาจเกิดขึ้นในประเทศ แม้ประเทศไทยจะไม่ใช่พื้นที่ที่มีความเสี่ยงสูง แต่เหตุการณ์ดังกล...
0

AI วาดสไตล์ Ghibli : OpenAI แอบดึงข้อมูลมาเทรนด์หรือเปล่า ประเด็นที่โลกไม่ควรมองข้าม
ฟีเจอร์ใหม่จาก ChatGPT ที่สร้างภาพสไตล์ Ghibli ทำเอาโลกอินเทอร์เน็ตสะเทือน แต่คำถามใหญ่คือ...นี่คือวิวัฒนาการของเทคโนโลยี หรือการทำลายจิตวิญญาณของศิลปะที่ Ghibli ยึดถือมาทั้งชีวิต ...
0
